Continuous testing of AI applications
December 12, 2024

As the industry shifts to a new paradigm, a persistent dependency now exists with the underlying technology that enables AI workflows - Large Language Models (LLM). Communication to an LLM occur through an API, which enable applications to directly send messages to the servers running the LLM model, and receive a response. The model providers have a pay-per-use business model, which charge a certain amount for each token. A token represents a part of a word, usually corresponding to 3.5 letters. Anthropic charges approximately $3 for 1,000,000 input tokens, and $15 for 1,000,000 output tokens.
In order to ensure robustness in applications, it is vital to perform end-to-end testing of the entire user flow, including the API call to an LLM. The aim is to replicate real user-behaviour as accurately as possible, which includes testing how the system performs under load. Moreover, a one-off test isn’t sufficient to ensure consistent correctness, as both the application and the LLM API will continue to iterate and change. As AI startups are scaling and seeing greater demand, it is now becoming exceedingly expensive to mimic user-load with the LLM APIs.
At Robin AI, we encountered this problem when we wanted to accurately test the new iteration of our Reports product. The goal of this project was to process 100,000 questions within the hour. With the average input length being 70,000 letters (20,000 tokens) and the average output length being 2600 characters (750 tokens), it costs about $0.07 to answer a question on a contract. Which means we would need to spend $7,000 for each test of this project. Even with prompt caching enabled, the cost would still be about $2,000. This motivated us to develop a mock API that mimics the behaviour of the real Anthropic API, and use this for testing. We used FastAPI and AWS to create an API endpoint. While the output of this mock API was now deterministic, it allowed us to model how the performance of the LLM API would impact our application. In order to do this properly, we first had to gather data on our usage of the Anthropic API.
Due to effective logging, we were able to measure the latency of the AI models. While it was easy to replicate a delay in the mock API that was indicative of this latency, we were still missing a crucial aspect - the errors. LLMs have a lot of constraints, on both capacity and throughput, and they can be prone to errors as a result. To test this effectively, we monitored the frequency of the different errors, and implemented our mock API to throw these errors with a similar probability. Not only did this allow us to continuously test our application, it allowed us to test our fallbacks and error handling as well.
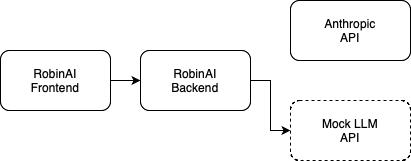
With the mock API in place, we were able to test our system end-to-end, continuously, and at load. We modelled how users interacted with RobinAI, and replicated their behaviour in our end-to-end testing suite. These tests are created by ingesting the behaviour of the Anthropic API, seeing the frequency of the errors and latency, to then replicate the same behaviour as a user would experience with our own mock API. To do this, we have a series of Playwright tests, which work in conduction with GraphQL requests to test every layer of the application stack.
In the future, we will perform this form of testing with all the AI agents we use. This can be done by similarly collecting all the metrics and data from these agents, and creating the respective Mock APIs. We intend to make this more modular too, in the case we switch one AI model for another, we can easily alter our mock API to replicate the new behaviour. This will result in a far more robust system, which will mitigate any adverse impact of LLM services being flaky.

