Earning Your Confidence: Evaluations at Robin
November 4, 2025
The Case for Evaluation
Here at Robin, we're building legal technology around a simple idea: your legal data should work as hard as you do. We believe the future of this field is when intelligence meets a reliable system of record - something that demands complex, specialized solutions. To make this vision a reality it’s not enough to trust that what we build will simply work - we must evaluate all our workflows, and look at performance beyond generic metrics as they typically fall short in high-stakes legal workflows.
That's why we built the Robin Evaluation Framework (REF). Rather than settling for broad metrics, we create evaluations based on real customer problems and purpose-built datasets that capture the unique nuances of legal work.
In the next sections we'll talk through what legal engineering is, what kind of data we use, how we test and how we automated this - from metadata enrichment and autonomous reasoning to complex Q&A and precise, lawyer-like editing. Finally, we’ll show why this testing allows us to pick and choose the best model for each distinct challenge that our customers face.
Our Evaluation Framework
Human-Led Legal Evaluation
Our Legal Engineering team is formed of legal professionals who combine their expertise with a deep understanding of the architecture and behaviour of Large Language Models (LLMs) and AI systems. They identify problem areas, design robust evaluation frameworks, and curate high-quality datasets that enable Robin to move quickly while maintaining confidence in the resulting product.
It’s a complex role that is akin to a legal product manager and a data scientist combined. Since they collaborate across functions to define what our technology should do (for example, what document relationship is tricky enough but common enough that we should tackle first?), they are naturally best placed to design how we should look at the resulting behaviour and when that fits with the customer’s expectations.
Building the Evidence Set: Curating Legal Test Data
So how do we know our systems do what they’re meant to do? It always starts from looking at the data. Our benchmarks are shaped by real client needs and support our exploration of open research challenges. Throughout this process, we carefully consider the intricacies embedded in the legal domain - such as interpreting annexes or related contracts, or reasoning about how legal authorities apply contractual terms. This thorough approach ensures our datasets truly reflect the complexity of legal work as it’s performed in practice.
However, if we relied on manual testing alone it would be impossible to move at a quick pace or deploy these systems at scale. That’s why we produce data that can be evaluated autonomously and reliably, reducing subjectivity, and enabling repeatable measurement at scale.
Screenshot from one of our annotation apps for contract review and editing
To support this, we invest in developing internal tools that ensure structured, high-quality annotation. For example, we’ve developed multimodal annotation apps for signatures and other contract elements, as well as tools that integrate textual annotation seamlessly with our processing pipeline to ensure that our data is as precise and objective as possible. During our annotation processes we also heavily invest in peer review of gold-standard datasets, such as a multi-contract chat experience comprising over 8,500 samples, through a “four-eye” process whereby annotations are reviewed and approved by more than one team member.
High-quality data is only half the battle. Once we have reliable test sets, we need to measure model performance in ways that matter to legal professionals - not just to data scientists.
What We Measure
While legal work must be factually correct and reliable, it also prioritises consistency and clarity. To develop some of the best-in-class evaluation methodology, we went directly to the source to understand the current pain points and failure modes with existing tools. We conducted a user study with a number of lawyers asking them two simple questions: "How would you approach a legal review step-by-step?" and "What do you look out for in an answer to grade it as satisfactory?"
These interviews, combined with our in-house Legal Engineering expertise, inspired the methodology for our novel internal evaluation app, LeMAJ (Legal LLM-as-a-Judge), which is specifically designed to emulate legal evaluation. This work was done in collaboration with our partners at AWS, where the team explored methods from simple fine-tuning, to creating mixture-of-expert judges, but more on this in the following section.
So how does this evaluation method work? Rather than evaluating entire answers holistically, LeMAJ breaks down LLM-generated answers into what we call "Legal Data Points" - self-contained units of information - and tags each with specific labels:
- Correct: accurate and relevant to the question
- Irrelevant: accurate but not relevant
- Incorrect: factually wrong or hallucinated
- Missing: should be present but is absent
This granular approach bridges summarisation techniques with legal reasoning requirements, producing interpretable metrics (Precision, Recall, F1, Correctness) that guide improvement efforts.
Alongside acting as a powerful tool for autonomous evaluation, one of the core strengths of the LeMAJ methodology lies in the ability of Legal Data Points to not only improve correlation between automatic evaluation and human evaluation but also correlation between humans. Legal questions often involve judgment calls and interpretation - two experienced lawyers can reasonably reach different conclusions on the same issue. But the LeMAJ methodology has improved inter-annotator agreement when looking at answer correctness by 11%, addressing a critical issue in the development of high-quality reference data and for the effective evaluation of assessment methods.
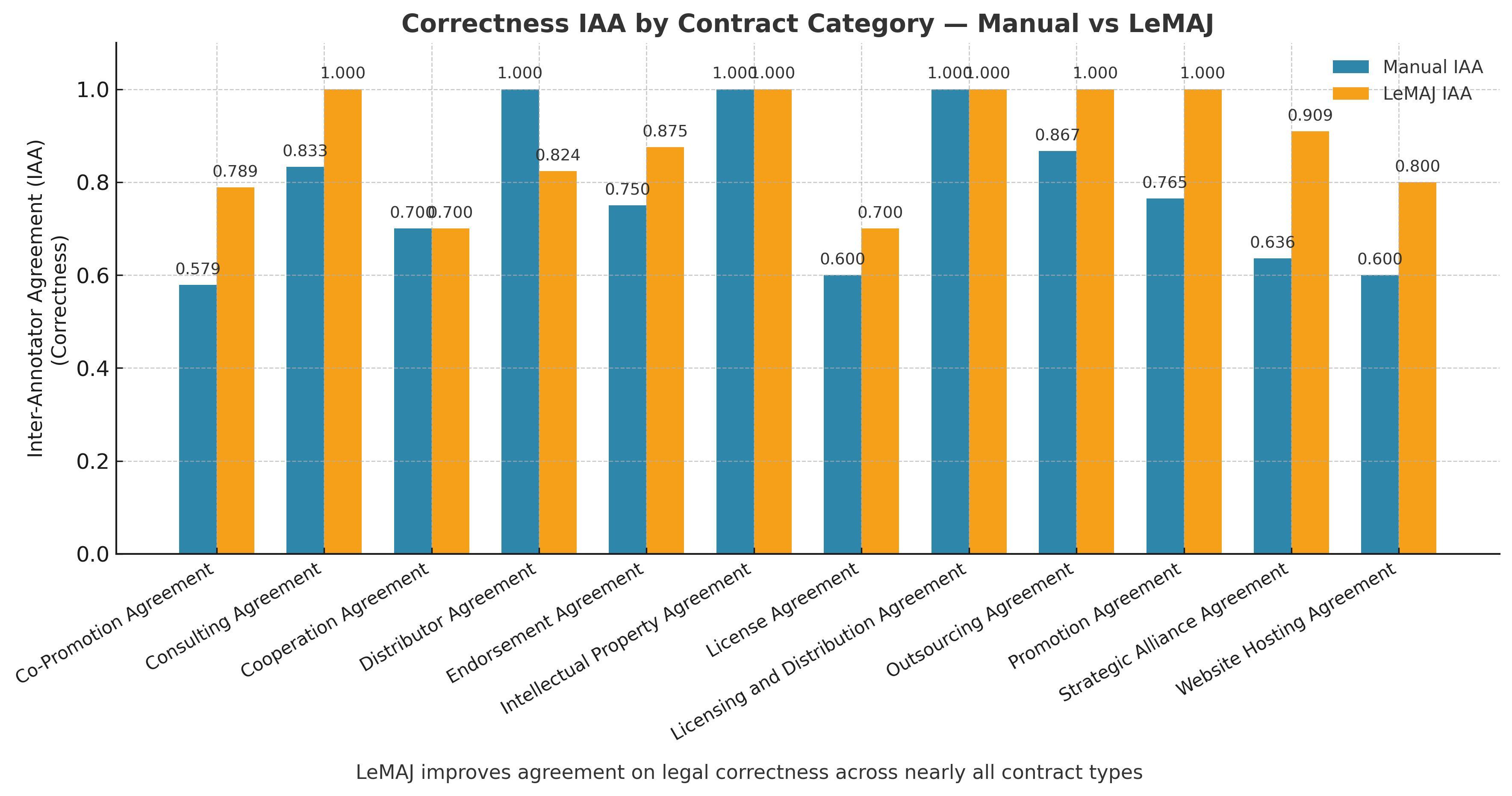
Inter-annotator agreement before and after LeMAJ
Finally, legal work requires attention not only to routine cases but also to the exceptional circumstances that demand careful consideration. Since legal data comes from many different sources with unique requirements, we continuously refine our evaluation process. We expand and adapt our datasets based on outcomes, uncovering gaps in model performance and identifying critical edge cases that generic benchmarks often miss. Rather than just tracking correctness, we monitor specific failure types like tabular reasoning, conditional logic, or complex contract relationships. This detailed tracking helps us identify exactly what needs improvement and creates a feedback loop that strengthens our models where legal expertise matters most. And since we’re dealing with generative models, uncertainty and reproducibility are par for the course - that’s why we implemented variability tests. These tests measure how consistent and reliable the models are across repeated runs, helping us set clear and accurate expectations for users.
By focusing on accuracy, reproducibility, and edge cases, our evaluation framework helps Robin’s Legal AI deliver dependable performance across the full range of legal complexities.
Automating the work
Once the nuances of what and how we're evaluating have been figured out, we move on to automating as much of the task as we can. As described above, we are trying to cover the product surface as much as possible, and having all of this as a manual evaluation would mean that less time can be spent on identifying shortcomings. To automate this we had two options - either use off-the-shelf methods, or build our own.
Off-the-shelf evaluation methods often rely on costly reference data or use standardised assessment tools that fail to capture the depth of legal reasoning. Legal tasks often involve interpretation, context, and judgment – qualities that are hard to measure with generic metrics alone. For example: In a Q&A exercise across hundreds of documents, annotating the exact passages of text required to answer the question enables us to automatically evaluate and optimise for correct answers containing the correct information – our researchers know that if this context is missing, the correctness of our final evaluations will be significantly impacted. Investing in this level of annotation allows us to run evaluations that are both replicable and scalable, helping us ensure model outputs are consistently measured to minimise subjectivity and allow us to continuously refine our models and focus human effort where it adds most value.
That’s why we worked with AWS to create LeMAJ. We talked before about the need for our Legal Data Points and what metrics this enables, here we’ll talk a bit more about the practical considerations for deploying LLM-as-a-Judge frameworks. Given the high computational cost of developing, deploying and maintaining large models as judges, as well as the reduction in speed during inference, we explored various options to reduce the size of the model while maintaining performance:
- prompt optimisation techniques
- data augmentation
- an LLM Jury framework involving multiple fine-tuned models
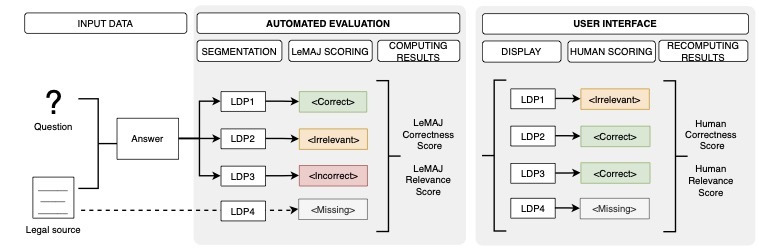
LEMAJ’s automated evaluation flow
We found that the LLM Jury framework was most performant, but when balancing against cost, fine-tuning with augmentation brought the best tradeoffs. If you want to dive deeper into our methodology you can find the paper at https://arxiv.org/html/2510.07243v1 or go to the NLLP workshop at the EMNLP conference where our paper was accepted, to hear Joseph Enguehard present this work.
And to give some insights into some of the time savings when using our automated system, we measured LeMAJ against a range of in-house human annotators and we found it to be highly effective, especially when involved in the triaging stage. The time savings in this case were in the range of 80% for our internal dataset, and 50% on LegalBench - a popular open source dataset used for legal Q&A. This is a huge jump from manual verification, and ensures that if manual verification is required, it happens on the more complex and nuanced cases.
These efficiency gains during development are significant, but they're just the beginning. The real test of any evaluation system is whether it can maintain quality standards after a product ships and lawyers start using it every day.
Ongoing Quality Control
An important point to make is that evaluations do not stop at launch. We test our products continuously – before deployment, during development, and in live environments – to ensure they perform reliably under real-world legal conditions.
To do this, we have built a regression testing framework that monitors the quality of our products ‘in the wild’, which is run regularly across our production systems. By integrating our LeMAJ tooling into this pipeline, we’ve devised a scalable and consistent way to simulate expert review so that we catch subtle shifts in performance. Some of the more important factors we're measuring are:
- sudden hallucinations
- shifts in accuracy, correctness, and relevance when comparing to a gold standard
- consistency in replies
- changes in context
This gives us early signals when something isn’t working as expected, allowing us to respond quickly and precisely. As a result, we are able to track quality over time, catch issues before they reach users, and continually raise the bar for what Legal AI can achieve.
What This Means for Legal Teams
Every metric we track, every test we run, and every dataset we curate serves one purpose: ensuring that when you use Robin, you can trust the results.
Building trust in Legal AI starts with choosing the right foundation. Selecting and maintaining the best models for specific legal tasks is a continual, data-driven process. We don’t just plug in the newest model and hope for the best. Legal work is too high-stakes for that. Instead, we use our specialised legal datasets, then test each model to see where it truly shines. Different legal tasks require different strengths, so we match models to the jobs they’re actually good at.
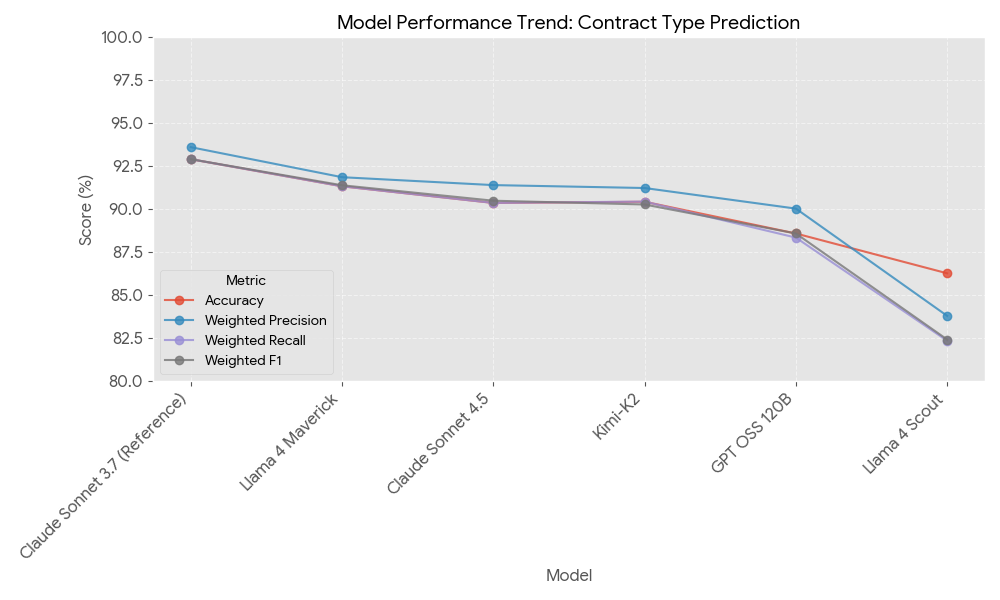
A snapshot of how Sonnet 4.5 compares against other baseline models - and why you don’t always have to change to the latest model
Across our evaluations, Anthropic’s Claude models continue to stand out. Each version brings different strengths: some handle dense legal reasoning beautifully, others excel at editing, research, or structuring complex answers. We don’t assume one model can do everything - we test, verify, and deploy the right model for the right moment.
Our evaluation process is rigorous, repeatable, and grounded in real legal practice. By constantly testing models against serious legal challenges, maintaining a growing library of task-specific benchmarks, and refining tools like LeMAJ, we make sure lawyers can trust what we ship. Legal professionals don’t need hype. They need reliable tools that help them work faster, think deeper, and stay confident in the details. That’s why we take evaluation so seriously - because every improvement should feel like progress you can rely on.
Want to see how we evaluate the specific features you use? Reach out to our team to learn more about our testing methodology, or explore our technical research at https://arxiv.org/html/2510.07243v1.

