The Hidden Network Behind Your Contracts (and Why It Matters)
October 31, 2025
Written by Marius Liwotto and Devon Willitts.
Introduction: The Silent Chaos Inside Contract Archives
Business relationships can be complex, and codifying that complexity into written agreements can lead to very convoluted, inter-related "families" of agreements—master agreements, amendments, renewals, supplemental agreements—that can be difficult to organize, search for, and interpret. Most organizations have no idea how these contracts are actually related, or what these relationships mean.
That’s a big issue, because understanding the sequence and intention of agreements is essential to correctly interpreting which legal terms are actually in force today. If you miss a key amendment or renewal, you might answer critical business questions with outdated information.
Here’s a simple example:
A Software Licensing agreement was signed January 1, 2012 that governs the scope of a license for software licensed from a software supplier to Company A. If an Amendment to that Software Licensing agreement, signed December 31, 2024, adds an Appendix that modifies the type of maintenance and support associated with the license, and that changes the financial terms and conditions, if that Amendment is not associated or archived with the original agreement, any attorney for Company A relying solely on the original agreement will be missing crucial information necessary to respond to questions about the relationship between the software supplier and Company A.
And this isn’t a rare edge case, it’s business as usual. So why are organisations still struggling with this? Let’s take a quick look at how traditional contract management systems handle this today (spoiler: not very well).
Managing the Mess: Today's Contract Management Challenges
Legacy systems, whether document repositories or traditional CLMs, lack the ability to automatically understand and associate related documents. Manual work is required to link them, and search or reasoning capabilities are limited or non-existent.
Legal and commercial teams today manage thousands of active agreements, many spanning decades, with numerous amendments and renewals in the commercial space, and other document types like limited partnership agreements and side letters in the asset management space. In some cases, determining the current contract version requires manually cross‑referencing ten or more related documents, often stored across disparate systems. This severely limits the ability to answer fundamental questions such as:
- What pricing terms are currently in effect?
- When does this agreement expire?
- Which obligations apply to which entities in which jurisdictions?
- What notice or renewal deadlines are upcoming?
The manual burden is significant. Teams must first locate and reconcile all related documents before substantive review can begin. Institutional knowledge often lives in the heads of individual team members, creating risk during turnover. While more sophisticated CLM systems allow users to manually store these connections, they leave critical gaps because they cannot automatically identify relationships or reason over linked documents to answer business questions. These inefficiencies translate into operational and financial exposure—missing renewal windows, incorrect pricing enforcement, or misinterpreted obligations. This complexity isn’t just administrative—it directly affects the accuracy of business decisions. That’s why we set out to automate the process of understanding how contracts relate to one another.
Goal: Automated Document Linking & Reasoning
At Robin our goal is to make the law simple. We took the tedious task of manually finding and organizing related contracts and developed an AI tool that can automatically identify when a document amends another. We decided to focus first on automatically detecting amendment relationships. Auto-identification is a hard task, and we wanted to make sure we got the amendment piece right before moving on to other relationship types, especially given their prevalence. To make sure this is useful in practice, we also developed new reasoning patterns that take amendments into account, so users can reason over "families" of related amendments, which solves a huge business need for our customers.
To summarise, we built an automated system that:
- Identifies amendment relationships at scale (”Auto ID”), and
- Uses those relationships to reason and answer user queries accurately.
Engineering Challenges
Developing this system required more than just good models, it demanded robust engineering to make it accurate, scalable, and extensible. As we moved from prototypes to production, we encountered a series of challenges that shaped how we designed and deployed the solution:
- Enterprises can have tens of thousands of contracts in their repositories;
- New contracts are uploaded continuously and the system must efficiently integrate incremental changes, including identifying how new contracts relate to previously uploaded contracts.
Auto ID Evolution
Our goal with Auto ID was to design a system that could automatically detect amendment relationships across thousands (or tens of thousands) of contracts reliably, incrementally, and economically enough to run continuously in production. Getting there required multiple iterations, each pushing against a different limit of scale, determinism, and interpretability.
We built and evaluated each version against a dataset of contracts annotated with ground-truth amendment relationships, comprising nearly 10,000 data points. This dataset spans different industries and contract types, allowing us to measure generalization performance and reason about tradeoffs between recall, precision, and operational cost. On average, each “base agreement” contains between two and three amendments, with the longest observed amendment chain extending to sixteen linked documents executed over a period of 6 years, which is a scenario that proved especially useful for stress-testing temporal and dependency modelling.
Iteration #1 — The “Single LLM Call” Baseline
Motivation:
We deliberately started with the simplest possible setup. The hypothesis was that a sufficiently capable LLM, when given a concise description of each contract (metadata + excerpts referencing other documents), could infer the full relationship graph in one pass. This allowed us to quickly explore edge cases and establish a quantitative baseline before engineering a complex system.
What we did:
- Extracted structured metadata (e.g. title) from each contract
- Parsed and included text snippets that mention other documents (e.g., “This Amendment No. 2 to the Master Agreement dated January 1, 2020…”).
- Concatenated these data points into a single prompt representing the “contract universe.”
- Asked the model to predict relationships: Which documents amend or are amended by others?
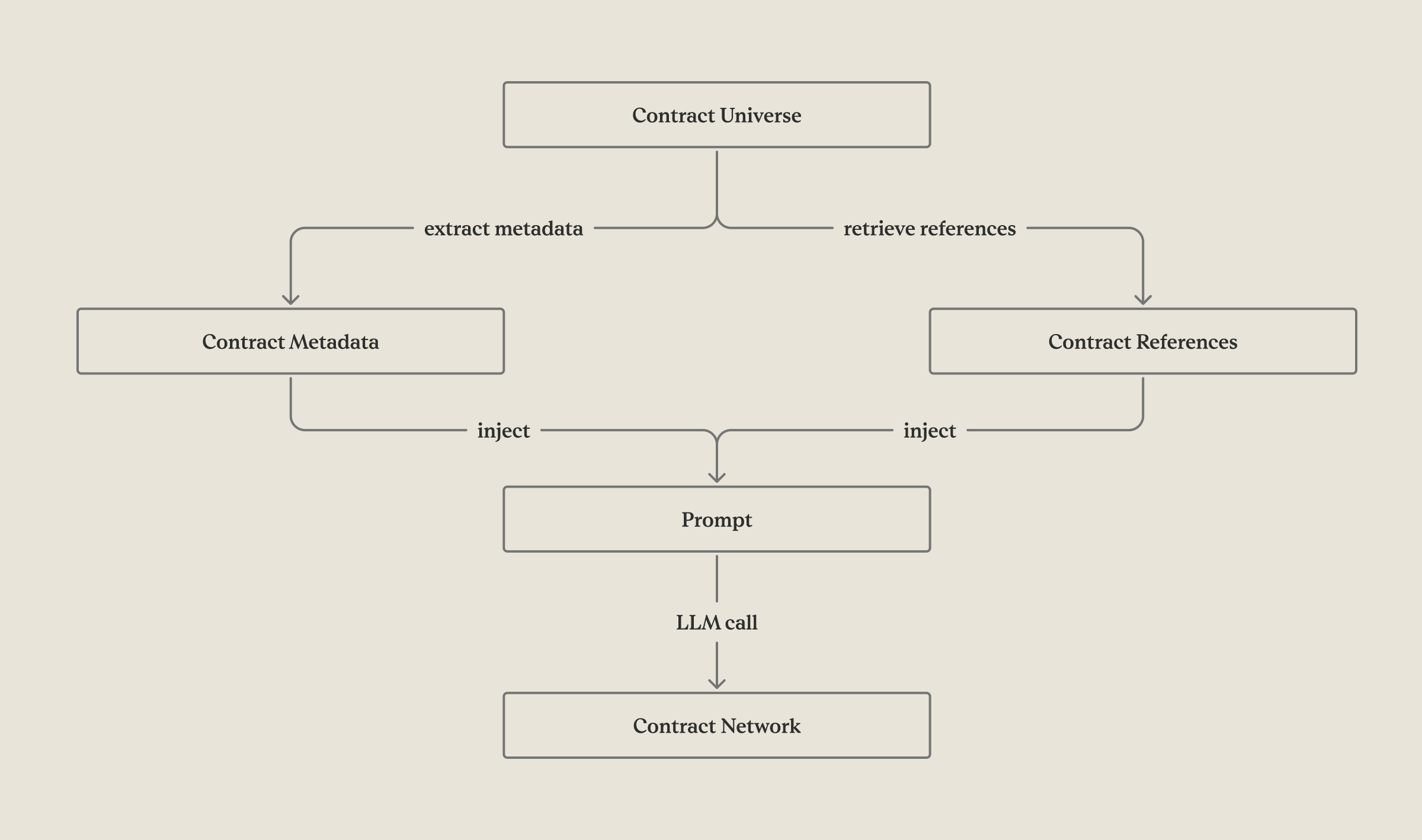
What worked:
- On small datasets (up to a few dozen contracts), the model performed well. It correctly linked amendments to their base agreements, even when naming conventions varied slightly.
- It gave us a quick understanding of failure patterns (e.g., ambiguous amendment titles, missing effective dates, partial references).
- Cost and latency were minimal; a single API call produced all relationships.
Where it broke:
- Context window saturation: With more than ~100 contracts, prompt size exploded. Important references were truncated or lost, breaking relational reasoning.
- Incremental update failure: When a new contract was uploaded, we’d have to re-run the entire inference which would have resulted in temporal inconsistency (relationships between contracts might change due to non-determinism of the model even if nothing in the underlying text changed).
- Trust & auditability: Because the model reasoned holistically, there was no localized evidence chain for each inferred relationship which made it hard to justify or debug why a given amendment was linked to a base.
- Prediction quality: The model was able to infer simpler relationships between contracts correctly, but failed in cases where relationships were more complex and less obvious from the provided metadata. It also frequently missed relationships between contracts.
Product decision:
Even though accuracy was promising for the simple case, it failed for more complex ones and also wasn’t operationally stable. We concluded that any model that required reprocessing the full contract universe per update would fail enterprise requirements for determinism, auditability, and incremental ingestion. It served its purpose as a baseline but wasn’t viable beyond research.
Iteration #2 — Clustering + Local LLM Calls
Motivation:
To overcome context window limits, we explored a clustering-first strategy. The idea: group contracts likely to be related, then run smaller, localized LLM calls within each cluster. This mimicked a sharded inference setup—partitioning the problem for scalability while maintaining relational context within clusters.
What we did:
- Generated embeddings for each contract using both semantic and lexical features: title embeddings, content embeddings, and structured metadata vectors (effective date proximity, shared counterparties, etc.).
- Clustered contracts using algorithms such as K-means, DBSCAN, and spectral clustering, experimented with different distance metrics.
- For each cluster, ran the same relationship-inference LLM prompt as in Iteration #1, but limited to that subset.
- merging all cluster-level networks to get the full contract network.
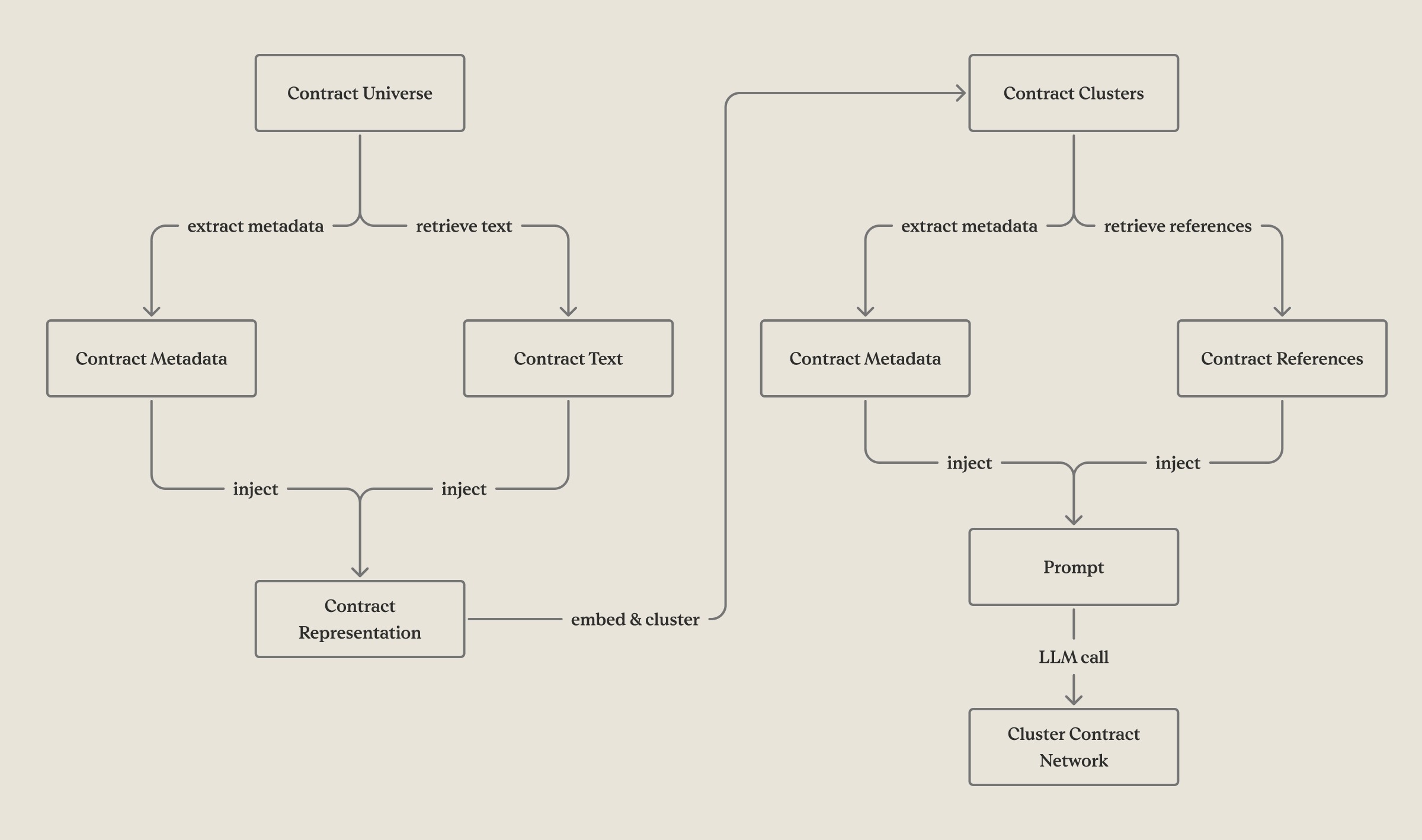
What worked:
- The system scaled better. Each cluster could be processed independently and in parallel, sidestepping global context window limits.
- It was still relatively cheap per iteration, since each LLM call operated on smaller contexts.
- For clients with moderately sized contract universes (hundreds to low thousands), the setup was practical and gave good initial coverage.
Where it broke:
- Parameter sensitivity: Clustering algorithms require hyper-parameters (e.g., number of clusters k, or the distance threshold eps in DBSCAN) that behave differently per client dataset. Finding stable defaults across clients would have been a considerable challenge.
- Prediction quality: The performance was better than in Iteration #1 due to smaller clusters, but still failed in cases where relationships were more complex and less obvious from the provided metadata. It also frequently missed relationships between contracts.
- Cluster prediction: Predicted clusters were often sub-optimal, they missed contracts which overall decreased recall.
- Incremental updates: When new contracts were uploaded, we either had to re-cluster everything (computationally expensive) or heuristically assign the new contract to a cluster (risking missed relationships). Neither path satisfied our production standards.
Unexpected learning:
Even though this approach seemed algorithmically appealing, semantic proximity is not the same as legal relatedness. Two contracts can look similar linguistically yet belong to entirely different families, while an amendment can have sparse textual overlap with its base agreement. The clustering signal was not legally meaningful enough.
Product decision:
We discarded this path after realizing that tuning, maintaining, and updating clusters would require too much manual oversight and the overall prediction quality was not as high as we would have hoped.
Iteration 3 — The “Legal Reasoning” Approach (Final Architecture)
Motivation:
After the previous iterations, we reframed the problem entirely. Instead of trying to infer all relationships at once, we asked: how would a lawyer do this? A lawyer doesn’t process all contracts together. They review one amendment, read the opening paragraph (e.g., “This Amendment No. 2 modifies the Agreement dated January 1, 2020”), and quickly understand the relationship. That process is local, incremental, and explainable, which is exactly what we needed at system level.
What we did:
- For each contract, independently:
- Classify whether it is an amendment or other type.
- Extract references to other contracts using text pattern recognition (e.g., “this amendment modifies…”) from amendments.
- Match references to known contracts in the dataset using metadata similarity.
- When a client uploads a new contract, we:
- Run the above pipeline immediately.
- If the base agreement for a detected amendment isn’t yet known, mark the amendment and hold it for future reconciliation.
- When a matching base agreement is later uploaded, automatically resolve the orphan.
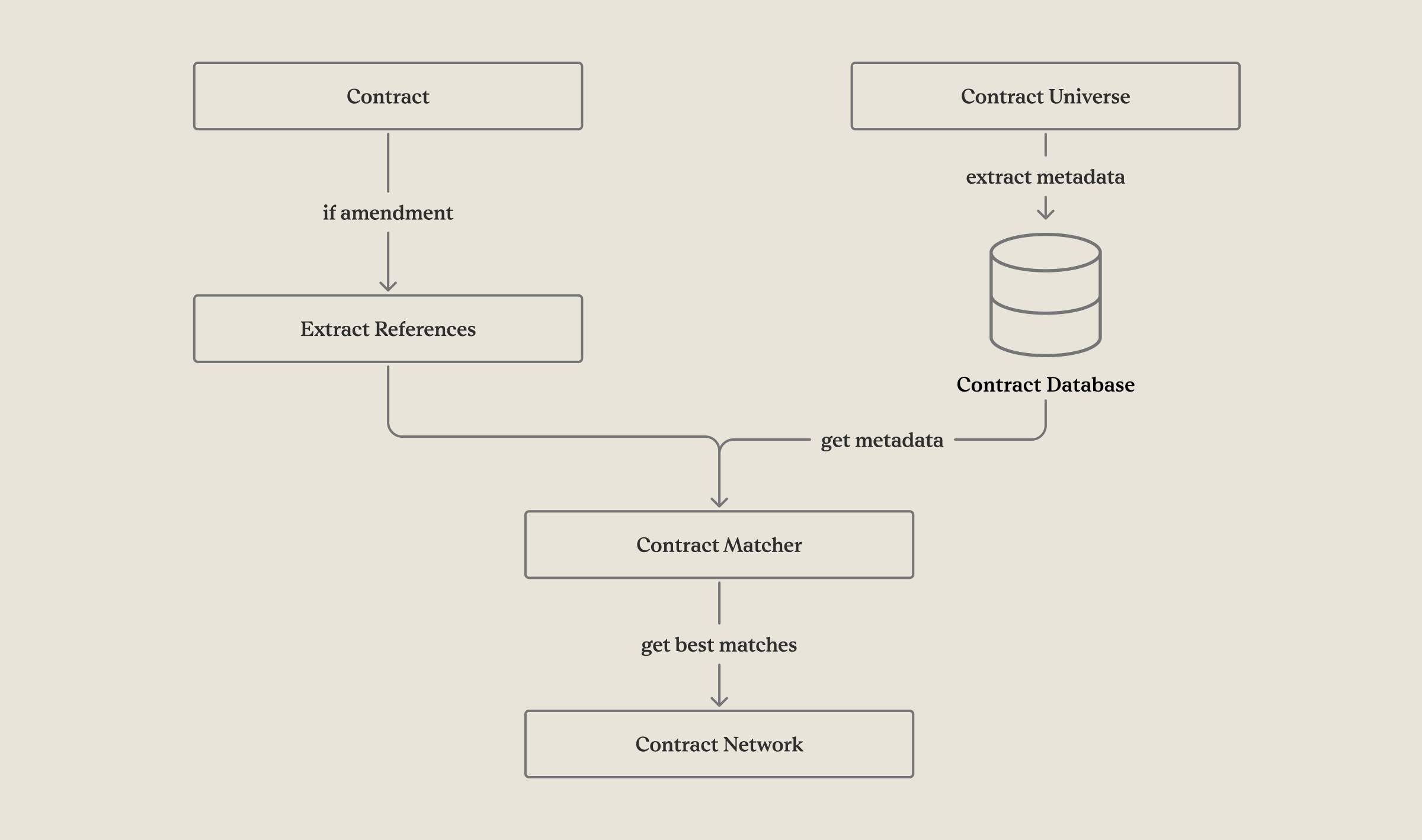
What worked:
- Unlimited scalability: Each contract is processed independently, allowing horizontal parallelization. No global re-run required.
- Incremental updates: New uploads only trigger local reasoning; the rest of the contract universe remains untouched.
- Interpretability: For each inferred link, we store the specific reference or sentence that triggered the relationship. This makes it auditable and explainable to users.
- Performance: Significantly higher F1 scores across all test sets compared to previous approaches, especially on complex amendment chains and cases with missing metadata.
Tradeoffs and cost:
- Requires one contract matcher call per contract, which increases total call volume. However, parallelization and asynchronous execution make this manageable.
- Total cost for 10k+ contracts is still minimal relative to the equivalent human effort.
- Slightly higher engineering complexity due to orchestration logic (managing orphans, metadata sync, reference stores), but the tradeoff is operational stability and production reliability.
Other advantages:
- The legal reasoning-like approach aligned well with our reasoning layer. Because we explicitly track amendment chains and effective dates, reasoning models can now see exactly which clauses are current and which were changed.
Product decision:
This design became our final architecture for Auto ID. It meets all enterprise constraints: scalable, auditable, deterministic, incremental, and explainable. In other words, it’s the first approach that works not just in a research setting, but in real client environments.
Reasoning Once Relationships Exist
Once the relationship graph is predicted, we can finally answer questions the way a lawyer would:
- for a given user question, we retrieve the relevant paragraphs from the base agreement and all amendments of that base agreements & we include metadata about each contract/amendment;
- We pass the explicit relationship graph in context;
- Then answer the user’s query.
We benchmarked this reasoning process using a dataset of 144 real Q&A pairs across complex amendment chains.
Results: Reasoning quality is excellent, especially on questions that historically trip up both CLMs and search-only AI like "what is the current pricing?", “who has termination rights after renewal?”, “what notice is required today?”
The system correctly understands amendment order and legal effect in a similar way to how an attorney would.
Conclusion: The Future of Contract Analysis
The reality today is that most contract management systems are still document storage systems that do not understand the underlying data.
They often are not “aware” which agreement is legally authoritative. They cannot track amendment chains. They force legal and commercial teams to manually reconstruct history every time a critical business question is asked. That manual effort is not just slow, but it is also fragile, non-repeatable, and entirely dependent on institutional memory. It is the opposite of how enterprise infrastructure should work.
Our research proves that it doesn’t have to stay this way.
Automatically understanding contractual relationships, including complex amendment trees, and reasoning across them accurately is now a solved problem at scale.
With a deterministic, legal-reasoning Auto ID system as the foundation, we can finally evolve contract systems from passive document storage systems into active legal intelligence layers.
This directly resolves the most painful realities of current contract management:
- No more manual reconstruction of “what is current.”
- No more lost institutional knowledge during staff turnover.
- No more surprises at renewal because nobody realized Amendment #7 modified the term length.
- No more misaligned internal understanding of pricing, commercial terms, or obligations.
- No more CLM search queries returning legally incorrect answers because they ignored amendments.
And this is just the beginning.
While our initial focus has been on amendment relationships, the same architecture naturally extends to agreements that affect renewals, restatements, novations, assignments, and other legally significant operations, which are the kinds of relationships that currently cause the most operational risk and financial leakage inside global enterprises.
The future state is not: “search your contracts better.” It is: “the system understands how your contracts evolve and provides answers based on the true legal reality.”
That is the shift from document management to contractual intelligence and it is finally practical, reliable, and enterprise-ready.

